Hi all
This is the first I’m using a emailing list so please bear with me if I’m doing anything wrong.
I’m looking for some support for a specific use case I have.
On our webpage we implemented an “auto suggestion” search based on the AnalyzingInfixSuggester. As we don’t have a lot of data I used the in-memory approach of Lucene. The final product looks something like this:
Now I was wondering if I can make the search more robust for e.g. typos. Is it e.g. possible that I get the “same” search results for the word sonstige (correct spelling) and sonnstige (incorrect spelling).
To give a better understanding how I implement this (maybe there are other things which can be improved) find the important code snippets:
Creating the SearchIndex
private InMemoryLuceneIndex createSearchIndex(int productVersion, LanguageEnum languageEnum) {
StopwordAnalyzerBase analyzer = null;
switch (languageEnum) {
case DE:
analyzer = new GermanAnalyzer();
break;
case EN:
analyzer = new EnglishAnalyzer();
break;
case IT:
analyzer = new ItalianAnalyzer();
break;
case FR:
analyzer = new FrenchAnalyzer();
break;
}
InMemoryLuceneIndex inMemoryLuceneIndex = new InMemoryLuceneIndex(new RAMDirectory(), analyzer);
final AwsXmlResponseGetRisikoklassifizierungen riskClassification = riskClassificationService.getRiskClassification(productVersion, languageEnum);
final List<RiskClassification> riskClassifications = riskClassification.getRisikoklassifizierungen().stream()
.map(risk -> RiskClassification.builder().isActive(!risk.isInNegativliste()).nogaCode(risk.getRisikonummer()).nogaDescription(risk.getBetriebsart()).nogaKeywords(risk.getStichworte()).build())
.collect(Collectors.toList());
inMemoryLuceneIndex.indexRiskClassifications(riskClassifications);
return inMemoryLuceneIndex;
}
SearchIndexImpl
@Slf4j
public class InMemoryLuceneIndex {
private Optional<AnalyzingInfixSuggester> analyzingInfixSuggester;
public InMemoryLuceneIndex(Directory memoryIndex, StopwordAnalyzerBase analyzer) {
try {
analyzingInfixSuggester = Optional.of(new AnalyzingInfixSuggester(memoryIndex, analyzer));
} catch (IOException e) {
log.error("unable to create the search index", e);
analyzingInfixSuggester = Optional.empty();
}
}
/**
* Ask for a suggestion
*
* @param searchTerm
* @return
*/
public Optional<List<RiskClassification>> suggest(String searchTerm) {
if (analyzingInfixSuggester.isPresent()) {
final List<Lookup.LookupResult> lookupResults;
try {
lookupResults = analyzingInfixSuggester.get().lookup(searchTerm, true, 10);
log.info("found {} results", lookupResults.size());
return Optional.of(lookupResults.stream()
.map(result -> {
try {
ByteArrayInputStream bis = new ByteArrayInputStream(result.payload.bytes);
ObjectInputStream in = new ObjectInputStream(bis);
return (RiskClassification) in.readObject();
} catch (IOException | ClassNotFoundException e) {
throw new Error("Could not decode payload :(");
}
})
.collect(Collectors.toList()));
} catch (IOException e) {
log.error("unable to lookup", e);
}
}
return Optional.empty();
}
/**
* build index for suggestion search
*
* @param riskClassifications
*/
public void indexRiskClassifications(List<RiskClassification> riskClassifications) {
log.info("add {} risks to index", riskClassifications.size());
analyzingInfixSuggester.ifPresent(suggester -> {
try {
suggester.build(new RiskClassificationIterator(riskClassifications.iterator()));
} catch (IOException e) {
log.error("unable to build the index", e);
}
}
);
}
}
thanks a lot for any pointers!
Cheers
Cyril
This is the first I’m using a emailing list so please bear with me if I’m doing anything wrong.
I’m looking for some support for a specific use case I have.
On our webpage we implemented an “auto suggestion” search based on the AnalyzingInfixSuggester. As we don’t have a lot of data I used the in-memory approach of Lucene. The final product looks something like this:
Now I was wondering if I can make the search more robust for e.g. typos. Is it e.g. possible that I get the “same” search results for the word sonstige (correct spelling) and sonnstige (incorrect spelling).
To give a better understanding how I implement this (maybe there are other things which can be improved) find the important code snippets:
Creating the SearchIndex
private InMemoryLuceneIndex createSearchIndex(int productVersion, LanguageEnum languageEnum) {
StopwordAnalyzerBase analyzer = null;
switch (languageEnum) {
case DE:
analyzer = new GermanAnalyzer();
break;
case EN:
analyzer = new EnglishAnalyzer();
break;
case IT:
analyzer = new ItalianAnalyzer();
break;
case FR:
analyzer = new FrenchAnalyzer();
break;
}
InMemoryLuceneIndex inMemoryLuceneIndex = new InMemoryLuceneIndex(new RAMDirectory(), analyzer);
final AwsXmlResponseGetRisikoklassifizierungen riskClassification = riskClassificationService.getRiskClassification(productVersion, languageEnum);
final List<RiskClassification> riskClassifications = riskClassification.getRisikoklassifizierungen().stream()
.map(risk -> RiskClassification.builder().isActive(!risk.isInNegativliste()).nogaCode(risk.getRisikonummer()).nogaDescription(risk.getBetriebsart()).nogaKeywords(risk.getStichworte()).build())
.collect(Collectors.toList());
inMemoryLuceneIndex.indexRiskClassifications(riskClassifications);
return inMemoryLuceneIndex;
}
SearchIndexImpl
@Slf4j
public class InMemoryLuceneIndex {
private Optional<AnalyzingInfixSuggester> analyzingInfixSuggester;
public InMemoryLuceneIndex(Directory memoryIndex, StopwordAnalyzerBase analyzer) {
try {
analyzingInfixSuggester = Optional.of(new AnalyzingInfixSuggester(memoryIndex, analyzer));
} catch (IOException e) {
log.error("unable to create the search index", e);
analyzingInfixSuggester = Optional.empty();
}
}
/**
* Ask for a suggestion
*
* @param searchTerm
* @return
*/
public Optional<List<RiskClassification>> suggest(String searchTerm) {
if (analyzingInfixSuggester.isPresent()) {
final List<Lookup.LookupResult> lookupResults;
try {
lookupResults = analyzingInfixSuggester.get().lookup(searchTerm, true, 10);
log.info("found {} results", lookupResults.size());
return Optional.of(lookupResults.stream()
.map(result -> {
try {
ByteArrayInputStream bis = new ByteArrayInputStream(result.payload.bytes);
ObjectInputStream in = new ObjectInputStream(bis);
return (RiskClassification) in.readObject();
} catch (IOException | ClassNotFoundException e) {
throw new Error("Could not decode payload :(");
}
})
.collect(Collectors.toList()));
} catch (IOException e) {
log.error("unable to lookup", e);
}
}
return Optional.empty();
}
/**
* build index for suggestion search
*
* @param riskClassifications
*/
public void indexRiskClassifications(List<RiskClassification> riskClassifications) {
log.info("add {} risks to index", riskClassifications.size());
analyzingInfixSuggester.ifPresent(suggester -> {
try {
suggester.build(new RiskClassificationIterator(riskClassifications.iterator()));
} catch (IOException e) {
log.error("unable to build the index", e);
}
}
);
}
}
thanks a lot for any pointers!
Cheers
Cyril
Attached Files:
-
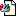 PastedGraphic-2.png (195 KB)
PastedGraphic-2.png (195 KB)