Hi all,
we are having an issue in our indexing pipeline time to time our
indexing process are stucked. Following text&picture is from jvisualvm
and it seems process is waiting at
sun.nio.fs.UnixFileSystem$FileStoreIterator.hasNext() method all the
time. we are using lucene 5.4.1 and java 1.8.0_65-b17.
what can be the reason of this?
Many Thanks
Tamer
text version
"
org.apache.lucene.facet.taxonomy.directory.DirectoryTaxonomyWriter.<init>()","100.0","73509067","73509067","3"
"
org.apache.lucene.facet.taxonomy.directory.DirectoryTaxonomyWriter.<init>()","100.0","73509067","73509067","3"
"
org.apache.lucene.facet.taxonomy.directory.DirectoryTaxonomyWriter.addCategory()","100.0","73509067","73509067","3"
"
org.apache.lucene.facet.taxonomy.directory.DirectoryTaxonomyWriter.internalAddCategory()","100.0","73509067","73509067","3"
"
org.apache.lucene.facet.taxonomy.directory.DirectoryTaxonomyWriter.addCategoryDocument()","100.0","73509067","73509067","3"
"
org.apache.lucene.facet.taxonomy.directory.DirectoryTaxonomyWriter.getTaxoArrays()","100.0","73509067","73509067","3"
"
org.apache.lucene.facet.taxonomy.directory.DirectoryTaxonomyWriter.initReaderManager()","100.0","73509067","73509067","3"
"
org.apache.lucene.index.ReaderManager.<init>()","100.0","73509067","73509067","3"
"
org.apache.lucene.index.DirectoryReader.open()","100.0","73509067","73509067","3"
"
org.apache.lucene.index.IndexWriter.getReader()","100.0","73509067","73509067","3"
"
org.apache.lucene.index.IndexWriter.maybeMerge()","100.0","73509067","73509067","3"
"
org.apache.lucene.index.ConcurrentMergeScheduler.merge()","100.0","73509067","73509067","3"
"
org.apache.lucene.index.ConcurrentMergeScheduler.initDynamicDefaults()","100.0","73509067","73509067","3"
" org.apache.lucene.util.IOUtils.spins()","100.0","73509067","73509067","3"
" org.apache.lucene.util.IOUtils.spins()","100.0","73509067","73509067","3"
"
org.apache.lucene.util.IOUtils.spinsLinux()","100.0","73509067","73509067","3"
"
org.apache.lucene.util.IOUtils.getFileStore()","100.0","73509067","73509067","3"
"
sun.nio.fs.UnixFileSystem$FileStoreIterator.hasNext()","100.0","73509067","73509067","3"
image version
we are having an issue in our indexing pipeline time to time our
indexing process are stucked. Following text&picture is from jvisualvm
and it seems process is waiting at
sun.nio.fs.UnixFileSystem$FileStoreIterator.hasNext() method all the
time. we are using lucene 5.4.1 and java 1.8.0_65-b17.
what can be the reason of this?
Many Thanks
Tamer
text version
"
org.apache.lucene.facet.taxonomy.directory.DirectoryTaxonomyWriter.<init>()","100.0","73509067","73509067","3"
"
org.apache.lucene.facet.taxonomy.directory.DirectoryTaxonomyWriter.<init>()","100.0","73509067","73509067","3"
"
org.apache.lucene.facet.taxonomy.directory.DirectoryTaxonomyWriter.addCategory()","100.0","73509067","73509067","3"
"
org.apache.lucene.facet.taxonomy.directory.DirectoryTaxonomyWriter.internalAddCategory()","100.0","73509067","73509067","3"
"
org.apache.lucene.facet.taxonomy.directory.DirectoryTaxonomyWriter.addCategoryDocument()","100.0","73509067","73509067","3"
"
org.apache.lucene.facet.taxonomy.directory.DirectoryTaxonomyWriter.getTaxoArrays()","100.0","73509067","73509067","3"
"
org.apache.lucene.facet.taxonomy.directory.DirectoryTaxonomyWriter.initReaderManager()","100.0","73509067","73509067","3"
"
org.apache.lucene.index.ReaderManager.<init>()","100.0","73509067","73509067","3"
"
org.apache.lucene.index.DirectoryReader.open()","100.0","73509067","73509067","3"
"
org.apache.lucene.index.IndexWriter.getReader()","100.0","73509067","73509067","3"
"
org.apache.lucene.index.IndexWriter.maybeMerge()","100.0","73509067","73509067","3"
"
org.apache.lucene.index.ConcurrentMergeScheduler.merge()","100.0","73509067","73509067","3"
"
org.apache.lucene.index.ConcurrentMergeScheduler.initDynamicDefaults()","100.0","73509067","73509067","3"
" org.apache.lucene.util.IOUtils.spins()","100.0","73509067","73509067","3"
" org.apache.lucene.util.IOUtils.spins()","100.0","73509067","73509067","3"
"
org.apache.lucene.util.IOUtils.spinsLinux()","100.0","73509067","73509067","3"
"
org.apache.lucene.util.IOUtils.getFileStore()","100.0","73509067","73509067","3"
"
sun.nio.fs.UnixFileSystem$FileStoreIterator.hasNext()","100.0","73509067","73509067","3"
image version
Attached Files:
-
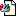 jjacbbjenleeibgf.png (132 KB)
jjacbbjenleeibgf.png (132 KB)