Hello!
This is a bit of a shot in the dark.
We are using Lucene 5.2.1 and have a "merging indexer" that merges a large
number of index segments produced upstream by a cluster of ingestion
workers. These workers ingest batches of text/web documents and indexes
them, then passes these small indexes as fragments to be merged into a set
of bigger indexes by the aforementioned merging indexer.
The merging indexer has a set of 30 indexes—it can be more, but I'm testing
w/ 30—and the incoming fragments are delivered to one of these indexes for
merging. (Note: The distribution of fragments across indexes is not even,
but rather based on certain criteria.) The number of incoming fragments is
quite large, 50K-100K per hour.
I'm running into a strange problem whereby the performance of the merging
(specifically, IndexWriter.addIndexes, IndexWriter.commitData, and
IndexWriter.commit calls) degrades over time. It starts off quite fast,
then after 10-15m degrades quickly, then over the next several hours
degrades further, but slowly, until settling down to a very low rate.
(Meanwhile processing of the incoming queue falls behind.)
Even more strangely, upon java process restart, the performance spikes back
up, and then the same degradation pattern repeats.
The performance looks like this (measured in fragments processed over time):
[image: image.png]
That's a graph of fragments processed per minute. Each one of those spikes
is after a process restart.
Can anyone think of an explanation for this?
This has been tested in AWS on various Linux instances using fast NVMe SSD
ephemeral storage.
Any insights or vaguely plausible theories would be considered
appreciated.Thanks!
This is a bit of a shot in the dark.
We are using Lucene 5.2.1 and have a "merging indexer" that merges a large
number of index segments produced upstream by a cluster of ingestion
workers. These workers ingest batches of text/web documents and indexes
them, then passes these small indexes as fragments to be merged into a set
of bigger indexes by the aforementioned merging indexer.
The merging indexer has a set of 30 indexes—it can be more, but I'm testing
w/ 30—and the incoming fragments are delivered to one of these indexes for
merging. (Note: The distribution of fragments across indexes is not even,
but rather based on certain criteria.) The number of incoming fragments is
quite large, 50K-100K per hour.
I'm running into a strange problem whereby the performance of the merging
(specifically, IndexWriter.addIndexes, IndexWriter.commitData, and
IndexWriter.commit calls) degrades over time. It starts off quite fast,
then after 10-15m degrades quickly, then over the next several hours
degrades further, but slowly, until settling down to a very low rate.
(Meanwhile processing of the incoming queue falls behind.)
Even more strangely, upon java process restart, the performance spikes back
up, and then the same degradation pattern repeats.
The performance looks like this (measured in fragments processed over time):
[image: image.png]
That's a graph of fragments processed per minute. Each one of those spikes
is after a process restart.
Can anyone think of an explanation for this?
This has been tested in AWS on various Linux instances using fast NVMe SSD
ephemeral storage.
Any insights or vaguely plausible theories would be considered
appreciated.Thanks!
Attached Files:
-
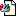 image.png (55.9 KB)
image.png (55.9 KB)